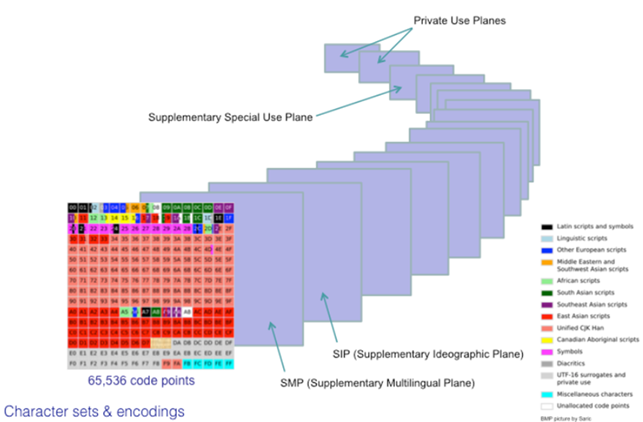
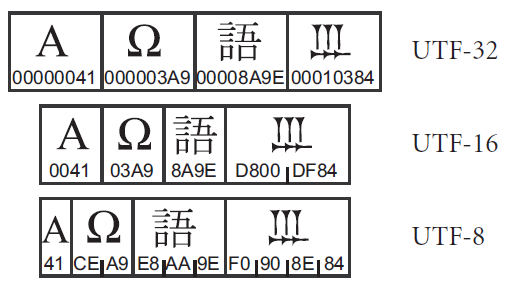
El gran número de caracteres codificados obliga a los desarrolladores de Unicode a agruparlos según sus características comunes, generando lo que se denominan “planos”. Cada plano consta de 65.535 caracteres y son:
- Plano básico o BMP. Contiene las codificaciones de los alfabetos más utilizados.
- Plano suplementario multilingüe o SMP. Dedicado a los alfabetos de lenguajes históricos menos utilizados y lenguajes técnicos.
- Plano suplementario ideográfico o SIP. Para caracteres muy raros.
- Plano de propósitos especial o SSP. Para caracteres de control no incluidos en el plano básico.
- Planos de uso privado para ser utilizados por fabricantes de software.
De una forma gráfica ésta es la representación de los planos: